打造專業(yè)電商網(wǎng)站,千喜網(wǎng)絡(luò)助您輕松起航
在當今數(shù)字化的商業(yè)環(huán)境中,擁有一家專業(yè)的電腦配件公司電子商務(wù)網(wǎng)站是拓展市場、提升銷量的關(guān)鍵一步。您是否正在為網(wǎng)站建設(shè)發(fā)愁?不必再花費高昂費用找人定制開發(fā),千喜網(wǎng)絡(luò)為您提供一站式現(xiàn)成解決方案,助您快速搭建穩(wěn)定、高效的在線銷售平臺。
千喜網(wǎng)絡(luò)憑借多年的行業(yè)經(jīng)驗,提供全面的基礎(chǔ)設(shè)施服務(wù),確保您的電商網(wǎng)站運行無憂:
- 云主機服務(wù):高性能的云主機保障網(wǎng)站快速加載與平穩(wěn)運行,支持高并發(fā)訪問,滿足促銷活動期間的流量需求。
- 云數(shù)據(jù)庫:安全可靠的數(shù)據(jù)庫服務(wù),確保訂單、客戶信息等數(shù)據(jù)存儲與管理的穩(wěn)定性,支持高效查詢與備份。
- 云存儲:大容量、可擴展的存儲方案,方便您上傳產(chǎn)品圖片、視頻等多媒體內(nèi)容,提升用戶體驗。
- 虛擬主機:經(jīng)濟實惠的虛擬主機選項,適合初創(chuàng)企業(yè)或小型網(wǎng)站,提供基本但穩(wěn)定的運行環(huán)境。
- 域名注冊:簡單快捷的域名注冊服務(wù),幫助您樹立品牌形象,讓客戶輕松找到您的網(wǎng)站。
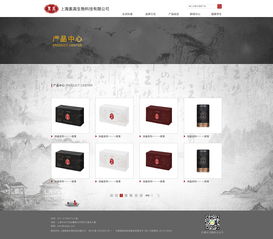
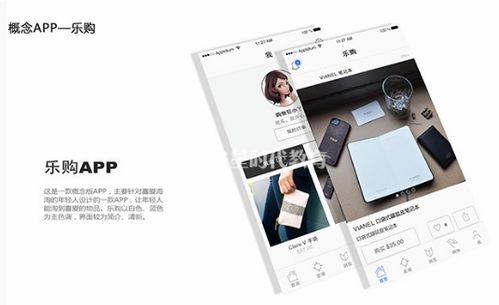
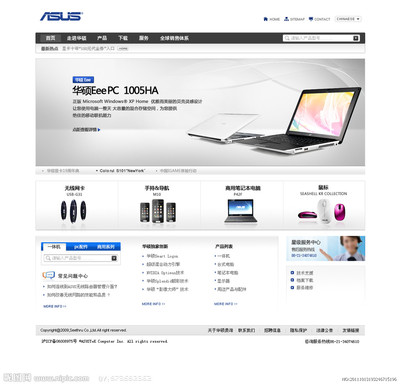
我們專注于計算機網(wǎng)頁設(shè)計,提供現(xiàn)成的電商模板和定制化選項,讓您的網(wǎng)站界面美觀、功能齊全,兼容各類設(shè)備。無需技術(shù)背景,您即可通過我們的平臺快速上線,專注于產(chǎn)品推廣和客戶服務(wù)。
選擇千喜網(wǎng)絡(luò),您將獲得可靠的技術(shù)支持與靈活的擴展方案。無論是初創(chuàng)企業(yè)還是成熟品牌,我們都能為您提供合適的服務(wù)組合,助力您的電腦配件業(yè)務(wù)在競爭激烈的電商市場中脫穎而出。立即行動,開啟您的在線銷售之旅!
如若轉(zhuǎn)載,請注明出處:http://m.fgetchr.cn/product/29.html
更新時間:2026-05-30 20:56:26